Analysing CV searches with Delicious
I put my CV online recently, and having the machine that serves this website (an iMac running Ubuntu Linux) sitting in the study, I can almost ‘feel’ the HTTP requests entering the house, going down the wire, and being served, like lumps travelling down a pipe in a Tom & Jerry cartoon.
So I was thinking about doing something useful with Apache’s access log, more than what I already have with the excellent Webalizer. Inspired (as ever) by Jon Udell‘s “ongoing fascination with Delicious as a user-programmable database“, I decided to pipe the access log into a Perl script and pull all the Google search referrer URLs that led to /qmacro/CV.html. For every referrer URL found, I grabbed the query string that was used and split it into words, removing noise. I also made a note of the top level domain for the Google hostname – a very rough indication of where queries were coming from.
But rather than create a database, or even an application, to analyse the results, I just posted the information as bookmarks to Delicious (after a simple incantation of *perl -MCPAN -e ‘install Net::Delicious‘ *- just what I needed, thanks!).
Delicious is a database, and by its very nature and purpose has a flavour that lends itself very well to loosely coupled data processing and manipulation. It’s about URLs and tags. It’s about adding data, replacing data, removing data. Basic building blocks and functions. Every item in the database has, and is keyed by, a URL, and as such, every item is recognised and treated as a first class citizen on the web. Even the metadata (tag information) is treated the same.
So what did I end up with? Well, for a start, I have a useful collection of referring CV search URLs, the collection being made via a common grouping tag ‘cvsearchkeywords‘ that I assigned to each Delicious post in addition to the tags derived from the query string.
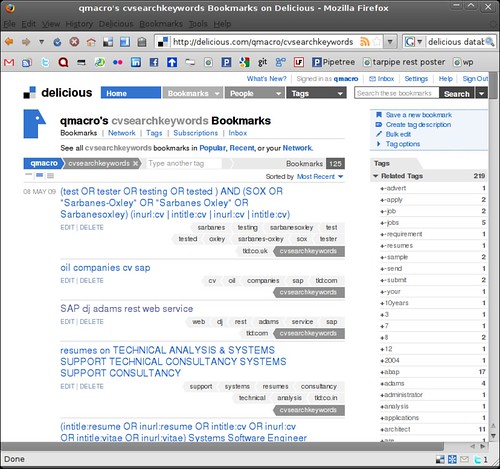
I also have a useful analysis of the search keywords, in the list of “Related Tags” – tags related to the common grouping tag. I can see right now for example that beyond the obvious ones such as “cv”, popular keywords are abap, architect and developer. What’s more, that analysis is interactive. Delicious’s UI design, and moreover its excellent URL design, means that I can drill down and across to find out what keywords were commonly used with others, for example.
That collection, and that analysis, will grow automatically as soon as I add the script to the logrotate mechanism on the server. That is, of course, assuming people remain interested in my CV!
And my favourite referrer search string so far? “How to write a CV of a DJ” :-)
- ← Previous
SAP everywhere! - Next →
Twitter's success