More Untappd data explorations with jq - my top ranking beer types (part 3)
This is a continuation of part 2 which you should read first.
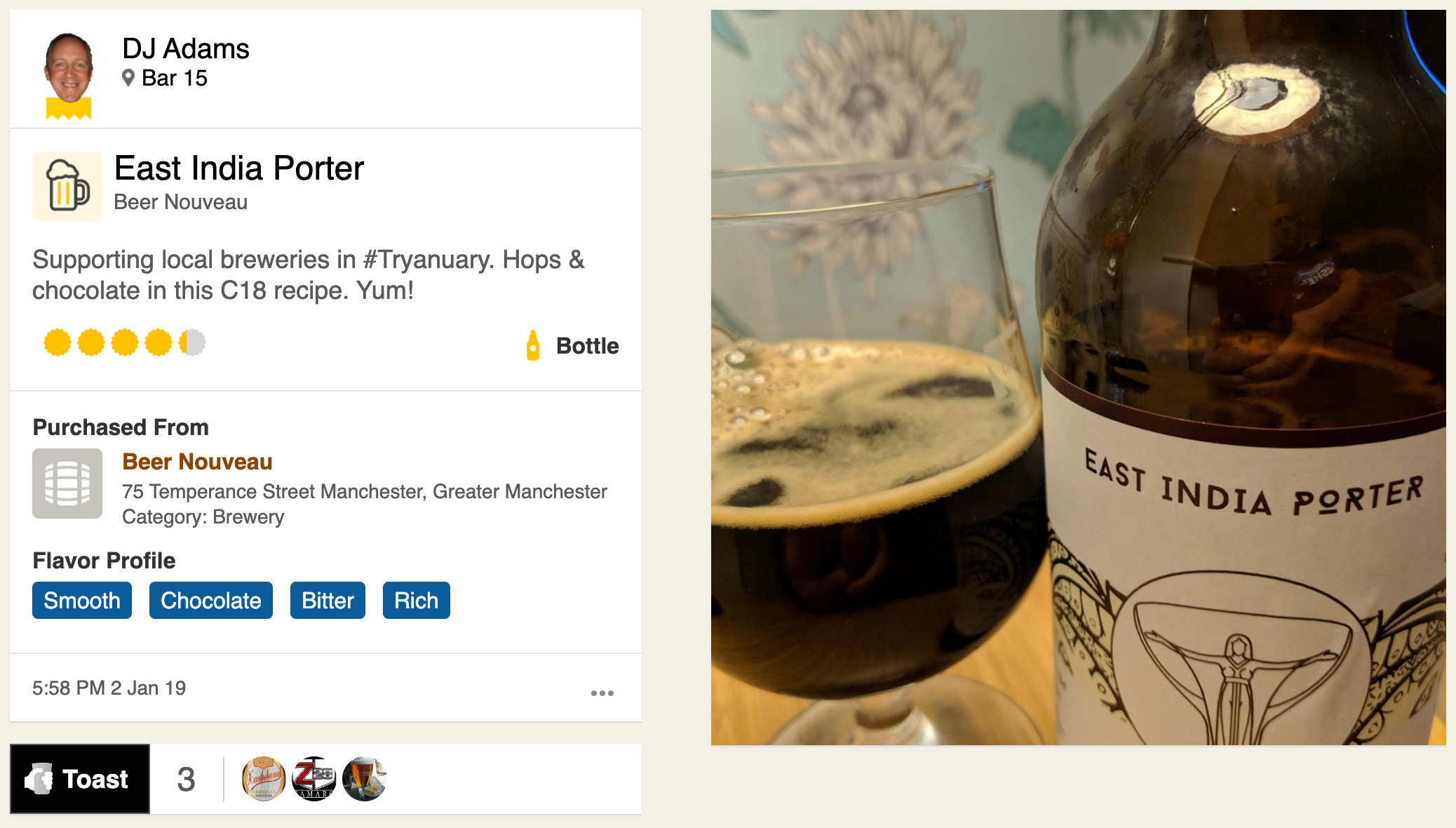
Part 2 finished with an array of category objects, each containing all the checkin ratings for that category, albeit in string form, with some empty strings:
[
{
"key": "Altbier",
"value": [
"4",
"3",
"3.75",
"3.5",
"3.25"
]
},
{
"key": "...",
"value": [
"...",
"..."
]
},
{
"key": "Winter Warmer",
"value": [
"",
"",
"4",
"4",
"4",
"3.5",
"4",
"4.25",
"3.25",
"4.25",
"3.75",
"3.4"
]
}
]This was achieved using a pattern now encapsulated into a function called arrange:
def major_type: split(" -") | first;
def arrange(k;v):
group_by(.[k])
| map({key: (first|.[k]), value: v});
map({ category: .beer_type|major_type, rating_score })
| arrange("category"; map(.rating_score))Dealing with bad data
So, about those rating values. I'll take the ratings for the Winter Warmer category as an example to work on, and I can get a list of those by extending the current filter like this:
def category: split(" -") | first;
def arrange(k;v):
group_by(.[k])
| map({key: (first|.[k]), value: v});
map({ category: .beer_type|major_type, rating_score })
| arrange("category"; map(.rating_score))
# Temporary selection of Winter Warmer ratings
| map(select(.key == "Winter Warmer"))|first|.valueI've deliberately put some whitespace (and a comment) before this temporary extension, to make it clear it's not permanent.
The output looks like this:
[
"",
"",
"4",
"4",
"4",
"3.5",
"4",
"4.25",
"3.25",
"4.25",
"3.75",
"3.4"
]OK, so it seems worthwhile building something to filter these values down to ones that are not null and to turn them from strings to numbers. While there isn't an explicit filter function, it's achieved by the combination of map and select, which is very common to see. In fact, I use it in this temporary extension: map(select(.key == "Winter Warmer")).
To be honest, I've often wondered why a simple syntactic sugar function isn't in the builtin library, something like this:
def filter(f): map(select(f));Then I could have expressed the above section like this:
filter(.key == "Winter Warmer").
Anyway, to the data. Filtering out anything except actual values could be done like this:
def category: split(" -") | first;
def arrange(k;v):
group_by(.[k])
| map({key: (first|.[k]), value: v});
map({ category: .beer_type|major_type, rating_score })
| arrange("category"; map(.rating_score))
# Temporary selection of Winter Warmer ratings
| map(select(.key == "Winter Warmer"))|first|.value
| map(select(length > 0))Which reduces the array of values appropriately:
[
"4",
"4",
"4",
"3.5",
"4",
"4.25",
"3.25",
"4.25",
"3.75",
"3.4"
]And conveniently, there's a function to parse input as a number, appropriately called tonumber (there's also tostring). Adding that to this filter like this:
def category: split(" -") | first;
def arrange(k;v):
group_by(.[k])
| map({key: (first|.[k]), value: v});
map({ category: .beer_type|major_type, rating_score })
| arrange("category"; map(.rating_score))
# Temporary selection of Winter Warmer ratings
| map(select(.key == "Winter Warmer"))|first|.value
| map(select(length > 0)|tonumber)gives us:
[
4,
4,
4,
3.5,
4,
4.25,
3.25,
4.25,
3.75,
3.4
]That's what we want! Worth putting into a function, don't you agree? How about calling that function numbers, and then using it in our temporary "Winter Warmer" extension:
def category: split(" -") | first;
def arrange(k;v):
group_by(.[k])
| map({key: (first|.[k]), value: v});
def numbers: (map(select(length > 0)|tonumber));
map({ category: .beer_type|category, rating_score })
| arrange("category"; map(.rating_score))
# Temporary selection of Winter Warmer ratings
| map(select(.key == "Winter Warmer"))|first|.value
| numbersTaking the average
While I'm in the mood for functions, how about one that will give the average of an array of numbers? I'll call it average and add it to untappd.jq:
def category: split(" -") | first;
def arrange(k;v):
group_by(.[k])
| map({key: (first|.[k]), value: v});
def numbers: (map(select(length > 0)|tonumber));
def average: (add / length) * 10 | floor / 10;
map({ category: .beer_type|category, rating_score })
| arrange("category"; map(.rating_score))
# Temporary selection of Winter Warmer ratings
| map(select(.key == "Winter Warmer"))|first|.value
| numbers
| averageI added some numeric fettling to the average function to ensure I'd end up with an average rating with a single decimal place.
So, what does this temporary extension now produce?
3.8Lovely!
I can now remove that extension and inject the two functions to the expression I'm sending in the second parameter for the call to arrange, like this:
def category: split(" -") | first;
def arrange(k;v):
group_by(.[k])
| map({key: (first|.[k]), value: v});
def numbers: (map(select(length > 0)|tonumber));
def average: (add / length) * 10 | floor / 10;
map({ category: .beer_type|category, rating_score })
| arrange("category"; map(.rating_score)|numbers|average)This produces what I was hoping for, a nice list of objects, one per category, with that category's average rating. Here's the first and last couple in that list (for brevity):
[
{
"key": "Altbier",
"value": 3.5
},
{
"key": "Barleywine",
"value": 4.4
},
{
"key": "Belgian Blonde",
"value": 3.7
},
{
"key": "Belgian Dubbel",
"value": 3.9
}
]Neatening up the results, and a main function
The nice thing about this sort of data structure is that it lends itself to further processing. In this case, I want to sort the categories by rating, in descending order.
I can achieve this with a call to sort_by, and then a call to reverse to swap the order.
While I'm at it, I'll also adopt a common programming approach of putting the main logic control in a main function and then calling that at the bottom of the script. It reminds me a lot of the Python style:
if __name__ == "__main__":
...So, here goes:
def category: split(" -") | first;
def arrange(k;v):
group_by(.[k])
| map({key: (first|.[k]), value: v});
def numbers: (map(select(length > 0)|tonumber));
def average: (add / length) * 10 | floor / 10;
def main:
map({ category: .beer_type|category, rating_score })
| arrange("category"; map(.rating_score)|numbers|average)
| sort_by(.value)
| reverse;
mainThis produces an array of categories, ordered by their average rating. Here are the first and last two in that list:
[
{
"key": "Rauchbier",
"value": 5
},
{
"key": "Freeze-Distilled Beer",
"value": 5
},
{
"key": "Märzen",
"value": 2.9
},
{
"key": "Pilsner",
"value": 2.7
}
]That's nice, but I will go one stage further and take advantage of the key/value pattern, using from_entries to condense that:
def category: split(" -") | first;
def arrange(k;v):
group_by(.[k])
| map({key: (first|.[k]), value: v});
def numbers: (map(select(length > 0)|tonumber));
def average: (add / length) * 10 | floor / 10;
def main:
map({ category: .beer_type|category, rating_score })
| arrange("category"; map(.rating_score)|numbers|average)
| sort_by(.value)
| reverse
| from_entries;
mainThis produces a neat list, like this:
{
"Rauchbier": 5,
"Freeze-Distilled Beer": 5,
"Chilli / Chile Beer": 5,
"Black & Tan": 4.5,
"Belgian Quadrupel": 4.5,
"Barleywine": 4.4,
"Wild Ale": 4.3,
"Specialty Grain": 4.3,
"Old Ale": 4.3,
"Bière de Champagne / Bière Brut": 4.3,
"Strong Ale": 4.2,
"Sour": 4.2,
"Stout": 4.1,
"Rye Wine": 4.1,
"IPA": 4.1,
"Belgian Tripel": 4.1,
"Winter Ale": 4,
"Smoked Beer": 4,
"Scotch Ale / Wee Heavy": 4,
"Red Ale": 4,
"Lambic": 4,
"Historical Beer": 4,
"Grape Ale": 4,
"Brown Ale": 4,
"Brett Beer": 4,
"Belgian Strong Dark Ale": 4,
"Traditional Ale": 3.9,
"Rye Beer": 3.9,
"Porter": 3.9,
"Pale Ale": 3.9,
"Mild": 3.9,
"Farmhouse Ale": 3.9,
"California Common": 3.9,
"Belgian Dubbel": 3.9,
"Winter Warmer": 3.8,
"Spiced / Herbed Beer": 3.8,
"Schwarzbier": 3.8,
"Belgian Strong Golden Ale": 3.8,
"Gluten-Free": 3.7,
"Fruit Beer": 3.7,
"Bock": 3.7,
"Bitter": 3.7,
"Belgian Blonde": 3.7,
"Scottish Export Ale": 3.6,
"Roggenbier": 3.6,
"Dark Ale": 3.6,
"Wheat Beer": 3.5,
"Table Beer": 3.5,
"Mead": 3.5,
"Kellerbier / Zwickelbier": 3.5,
"Honey Beer": 3.5,
"Cream Ale": 3.5,
"Cider": 3.5,
"Altbier": 3.5,
"Blonde Ale": 3.4,
"Scottish Ale": 3.3,
"Kölsch": 3.3,
"Golden Ale": 3.3,
"Lager": 3.1,
"Shandy / Radler": 3,
"Märzen": 2.9,
"Pilsner": 2.7
}That's very satisfying!
What's next
Well I think I'm there, basically. But something bothers me. I know my favourite style is more towards the India Pale Ale (IPA) variety, but ranking well above that style (both IPAs and Imperial IPAs) are some rarer categories, such as Rauchbier and Freeze-Distilled Beer. Why is that? That's what I'll investigate in part 4.