Setting up my own Cloud Foundry
It was more difficult that I expected to get a local Cloud Foundry (CF) up and running, but I got there in the end. Here's a brief description of my journey.
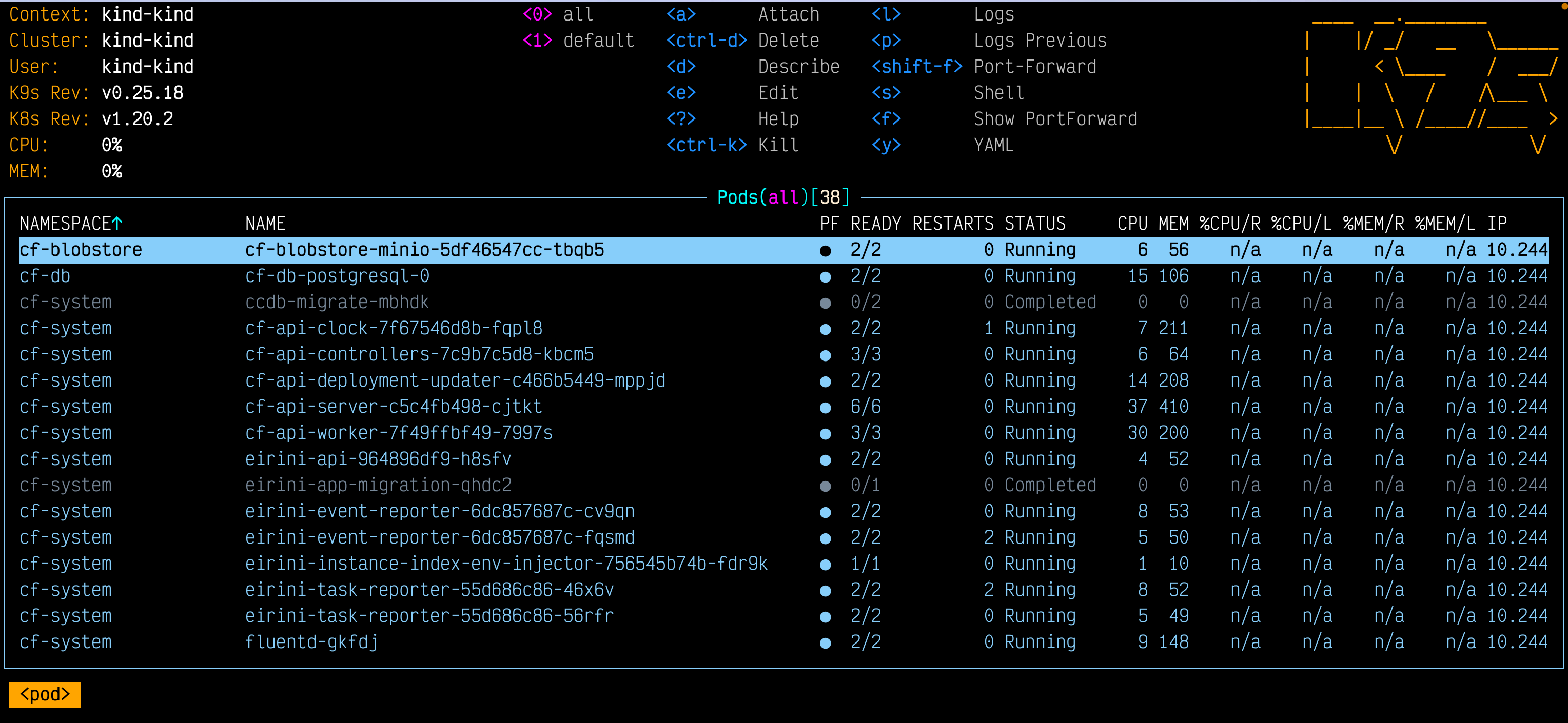 CF on Kubernetes in Docker, on my laptop
CF on Kubernetes in Docker, on my laptop
As a developer with access to SAP's Business Technology Platform, I already have free access to multiple runtime environments and services. These environments include Kubernetes, via Kyma, and Cloud Foundry.
While exploring service brokers and service consumption on SAP Business Technology Platform recently, with a view to understanding the context and role of the SAP Service Manager (another open source project in the form of Peripli), I wanted to go beyond the developer level access I had to a Cloud Foundry runtime.
In essence, I wanted my own Cloud Foundry environment instance, that I controlled and administered. That way I would be able to explore the SAP Service Manager, and service catalogues and marketplaces in general, in more detail.
PCF Dev no longer an option
In the past, I've used PCF Dev, the classic go-to for getting a laptop-local Cloud Foundry up and running. I was successful in the past, and used it to explore some Cloud Foundry aspects. But this time, I fell at the first hurdle. One of the early steps to getting such a local version up and running is to install a plugin for the cf CLI. This failed, basically due to the official location where the plugin was stored returning 404 NOT FOUND responses.
My searches on Stack Overflow (see e.g. this answer) and in various Slack channels had me coming to the conclusion that PCF Dev was, unfortunately, a non-starter today. Folks had tried in vain to compile and use the binary portion of the plugin, but had then hit issues further down the line. The fact that the official site sports a "End of availability" badge also helped confirm this.
CF on Kubernetes
There was hope, though, as I discovered a couple of initiatives that involved running CF on Kubernetes. That may strike one as odd at first sight, running one environment within another, but this is not really much different to my first environment, when I joined Esso as a graduate in 1987, where we ran various applications and systems, including SAP R/2, on the MVS/XA operating system ... which ran within the VM/CMS operating system.
And after all (cue generalisation and waving my arms about in the air) while CF is a developer-centric deployment and runtime platform, Kubernetes is a more generalised container orchestration system.
I proceeded to inhale as much information as I could on this topic, specifically about the two initiatives, which are:
- KubeCF - "Cloud Foundry Packaged for Kubernetes"
- cf-for-k8s - "cf push for Kubernetes"
Running Kubernetes locally
Another aspect that had me scratching my head a little was the different ways I could run a local Kubernetes cluster. I considered and tried two possibilities, and both of them, independently of me trying to get CF running on them, worked well.
One is minikube, which uses a virtual machine manager. The other is kind, short for "Kubernetes in Docker". This adds yet another layer for my brain to get itself around (I'd essentially be running CF in Kubernetes in Docker, which itself -- on this macOS laptop -- is essentially a Linux virtual machine).
Getting things up and running
I started out on the KubeCF path, but had countless issues. Perhaps not surprising in the end, because while the main KubeCF landing page looks all shiny and up to date, when you dig down just one layer to the GitHub repository, you notice the ominous message "This repository has been archived by the owner. It is now read-only.". It wasn't an auspicious start, and I soon abandoned my attempts in that direction, and pivoted to cf-for-k8s.
There's a great article Getting Started with Cf-for-K8s which I found and followed. My laptop had comfortably more than the minimum hardware requirements (and as you'll see later, I think those minimum requirements are a little "light"). Kubernetes as a platform is complex, perhaps partly because it's built from different tools and projects. So the tool prerequisite list was a little longer than I'm used to seeing. That said, I had no issues, mostly thanks to brew packaging:
- I installed
kindwithbrew install kind(via this page) and the BOSH CLI withbrew install cloudfoundry/tap/bosh-cli. - I also used
brewto installyttandkapp; in fact, these tools, along with others, are collected together in a package called Carvel, which "provides a set of reliable, single-purpose, composable tools that aid in your application building, configuration, and deployment to Kubernetes", and I installed them all via thevmware-tanzu/carveltap. - I already had the rest of the tools:
git, thecfCLI (I use version 7 these days). - I also already had an account on Docker Hub; this was to act as a container registry.
I also (re)installed k9s, a great Terminal User Interface (TUI) for monitoring and managing Kubernetes clusters. You can see k9s in action in the screenshot at the start of this post.
I followed the Getting Started with Cf-for-K8s instructions in the to the letter, and was soon deploying cf-for-k8s with kapp.
Issues along the way
It wasn't entirely smooth sailing, but I managed to deal with the issues that came up. Here's what they were.
cf-api-server and cf-api-worker pods unstable
Once the kapp based deployment was complete, I noticed that the cf-api-server and cf-api-worker pods were unstable. Sometimes they'd show the "Running" status, with all required instances running. Other times they'd switch to "CrashLoopBackoff". During this latter status, which was most of the time (due to the backoff algorithm, I guess), any cf commands would fail with a message saying that the upstream was unhealthy.
Digging into the containers, the 'registry-buddy' seemed to be the component having problems, in both cases. It seemed that this component was involved in talking to the container registry, Docker Hub in my case. I eventually found this issue that described what I was seeing in my setup: container registry-buddy in cf-api-server and cf-api-worker pods always stop.
The user nicko170 made an extremely useful comment on this issue suggesting that it was a timeout issue and also providing a fix, which involved adding explicit timeoutSeconds values to the configuration.
I implemented this exact fix on my fork of the capi-k8s-release repo, and then modified the entry in my vendir.yml file to point to my own modified fork:
---
apiVersion: vendir.k14s.io/v1alpha1
kind: Config
minimumRequiredVersion: 0.11.0
directories:
- path: config/capi/_ytt_lib/capi-k8s-release
contents:
- path: .
git:
url: https://github.com/qmacro/capi-k8s-release
ref: 9ec99f41bded21a6fbe496323dbcb225d927b158I did see a vendir.lock.yml file while making this fix; I'm not sure where it came from, but assuming it was similar to the package-lock.json file mechanism in Node.js, and had similar effects, I removed it, to give the modification to vendir.yml the best chance of taking hold.
This fixed the stability of the cf-api-server and cf-api-worker pods. Great, thanks Nick!
Instability of ccdb migration pod
This didn't happen on my first attempt (where I started to notice the cf-api-server and cf-api-worker issues), but it did on my subsequent attempts, when I'd removed the cluster (with kind delete cluster) and started again. I got timeout issues relating to the pod that seemed to be responsible for some ccdb migration activities (whatever they are).
Digging around it seemed to be possibly related to there not being enough resources allocated to the cluster for it to complete the tasks assigned. So I modified my Docker Engine configuration to increase the RAM and CPU resources as follows:
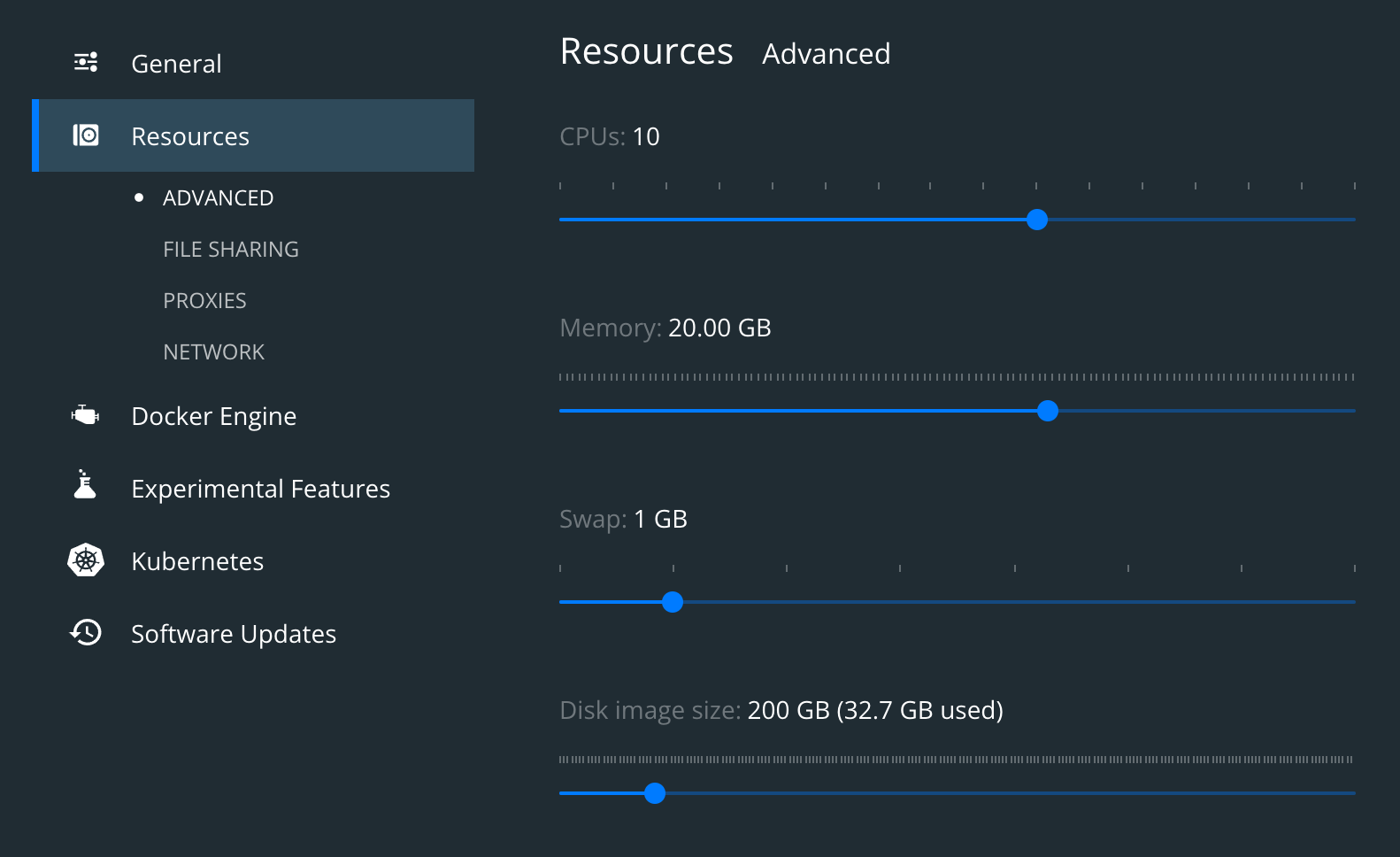
After starting again, this seemed to fix the timeout issue with this pod.
More issues with cf-api-server
Once I'd got that out of the way, I noticed that while cf-api-worker was now stable, cf-api-server was still having issues. Looking into the logs, it wasn't the registry-buddy container that was in trouble this time, it was the cf-api-server container itself.
There were logs that ostensibly looked like they were from a Ruby app, and expressed complaints about some missing configuration in the rate_limiter area. I did a quick search within my installation directory and found this to be in a single configuration file:
config/capi/_ytt_lib/capi-k8s-release/config/ccng-config.lib.yml
The pertinent section looked like this:
rate_limiter:
enabled: false
per_process_general_limit: 2000
global_general_limit: 2000
per_process_unauthenticated_limit: 100
global_unauthenticated_limit: 1000
reset_interval_in_minutes: 60The configuration entries that were apparently missing, according to the log, were general_limit and unauthenticated_limit. Looking around, I found these properties on the Setting the Rate Limit for the Cloud Controller API page in the CF documentation. So they did seem to be valid properties.
It was getting late so I just modified that ccng-config.lib.yml file to add the two missing properties, as copies of the global_ versions that were already there.
I then rebuilt the deployment configuration and deployed once more. This basically involved just running this invocation again:
kapp deploy -a cf -f <(ytt -f config -f ${TMP_DIR}/cf-values.yml)Note that the deployment configuration rebuild is done by the ytt invocation, which is inside the <( ... ) process substitution part of the invocation.
This seemed to satisfy the cf-api-server into not complaining any more.
Success
At this point, everything became eventually stable. On my laptop, this was taking between 5 and 10 minutes. It remained stable and I was able to authenticate with cf, create an organisation and space, and deploy (via cf push) a simple test app.
That was quite a journey, and I've learned a lot along the way. Now comes the real learning, at the Cloud Foundry administrative level!
- ← Previous
Exercism and jq - Next →
Understanding jq's reduce function