Shell power and simplicity
Sometimes we overlook the power of the shell, because the terminal context in which it's used is seen as outdated. That's far from the truth; in fact I think it would be a shame to lose sight of some fundamental and simple shell programming concepts which are as relevant, if not more, today, as they were ten years ago.
The inspiration for this post
Earlier this morning, on my travels, a tweet from David Ruiz Badia caught my eye:
"Artificial intelligence + code repository on git = Autocomplete models when coding by @timoelliott Experience Intelligent Summit Barcelona #Intelligententerprise #experiencemanagement #sapchampions @SAPSpain"
It wasn't the text or the main subject of the tweet, but the code on the slide that was shown in the accompanying picture:
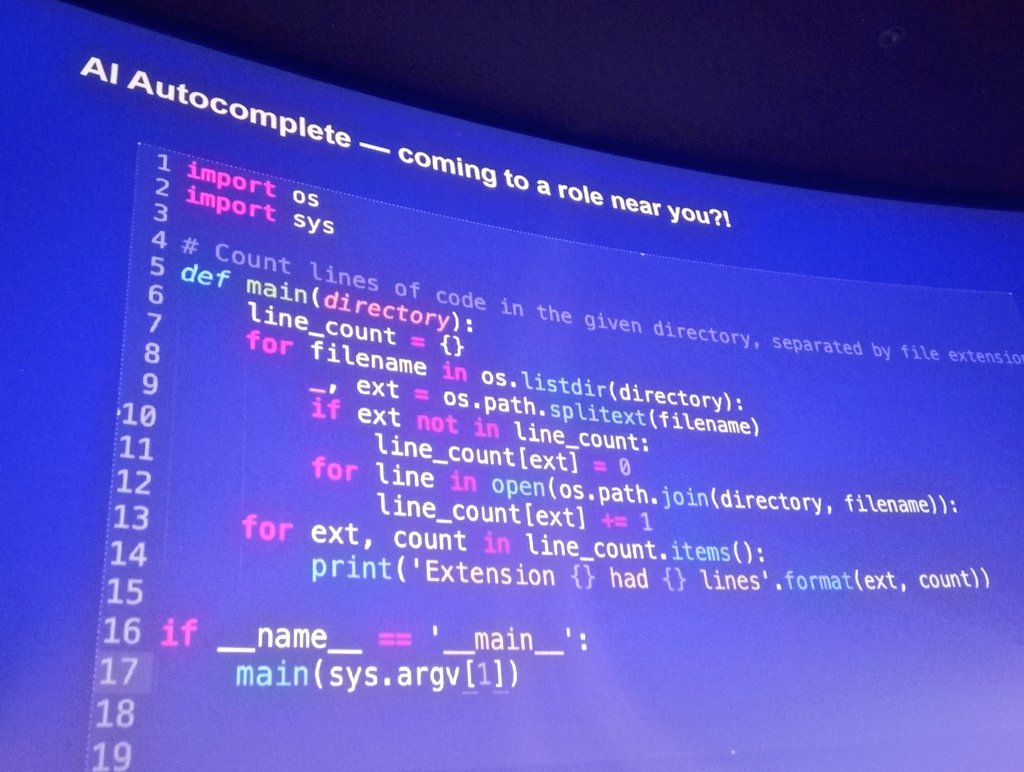
Luckily the code on the slide is clear enough to read, so I won't reproduce it here.
The challenge
It's Ruby, and fairly simple code to sum up the total number of lines in files, by file type (extension), in a given directory. So for example, assume you have the following files, each containing the indicated amount of lines:
a.txt (3 lines)
b.txt (4 lines)
c.dat (1 line)
d.txt (2 lines)
e.dat (5 lines)
What you want this program to produce is something like this:
dat -> 6
txt -> 9
Thinking of files and lines immediately switched my brain to shell mode, where one part of the shell philosophy (do one thing and do it well - also attributable to the Unix philosophy in general) gives us the wc program, which produces word, line, character and byte counts for files (and that's about it).
Another part of the philosophy is "small pieces loosely joined", which, in conjunction with the pipeline concept, and combined with the wonderful simplicity of STDIN (standard input) and STDOUT (standard output), gives us the ridiculously useful ability to send the output of one command into the input of another.
This ability might seem somewhat familiar, particularly if you've been discovering the fluent interface style of method chaining in API consumption, as recently shown in how the SAP Cloud SDK is used - here's an example from a tutorial "Install an OData V2 Adapter" which is part of one of this year's SAP TechEd App Space missions "S/4HANA Extensions with Cloud Application Programming Model":
BusinessPartnerAddress
.requestBuilder()
.getAll()
.select(
BusinessPartnerAddress.BUSINESS_PARTNER,
BusinessPartnerAddress.ADDRESS_ID,
BusinessPartnerAddress.CITY_NAME,
)
.execute({url:'http://localhost:3000/v2'})
.then(xs => xs.map(x => x.cityName))
.then(console.log)Anyway, I'm always happy for opportunities to practise my basic shell skills and Unix commands, so I thought I'd have a go at "finishing the sentence" in my mind, the one that had started with wc, and write a pipeline that would do the same thing as that lightly pedestrian Ruby code.
I realise I don't have much context as to why the code is there or why it looks like it does - it relates to machine learning powered autocomplete features in code editors, so was likely something simple enough for the audience to understand but verbose enough to be of use as an example.
Getting the line counts
Starting with wc on the files, using the -l switch to request lines, we get this:
→ wc -l *
3 a.txt
4 b.txt
1 c.dat
2 d.txt
5 e.dat
15 total
→There's nothing other than these 5 files in this directory, as you might have guessed.
That's something we can definitely work with - we need to sum the numbers by file extension (txt or dat in this example).
Stripping the extraneous info
If we're to pass the output of wc directly into another program to do the summing, we may trip ourselves up because of this line at the end of the wc output:
15 total
We don't want the value 15 from that total summary line to be included. So we use another program to strip that line out, and pipe wc's output into that.
On GNU-based Unix or Linux systems, we can use the head program to do that for us. head will display the first N lines of a file. The GNU version of head contains a flag -n that can take a negative number, to work backwards from the end of the file, so that we can do this:
→ wc -l * | head -n -1
3 a.txt
4 b.txt
1 c.dat
2 d.txt
5 e.dat
→The nice thing about this approach is that we will always strip off just the last line.
Observe how the output of wc has been piped into the input of head. If you wanted to do this in a very inefficient but more or less equivalent way, using an intermediate file, you'd have to do this:
→ wc -l * > intermediatefile
→ head -n -1 intermediatefile
3 a.txt
4 b.txt
1 c.dat
2 d.txt
5 e.dat
→Here, the > symbol is redirecting the STDOUT from wc to a file called intermediatefile, and the head program reads from STDIN, or, if a filename is specified as it is here, will read from that file.
On macOS, a decendant of BSD Unix, the GNU version of head isn't available, and so we cannot avail ourselves of the -n -1 approach. Instead, we'd use the grep command which in its basic form prints lines that match (or don't match) a pattern. We can use grep's -v switch to negate it, i.e. to get it to print lines not matching the pattern, and specify " total$" as the pattern to match (the dollar sign at the end of the match string is a regular expression symbol that anchors the text " total" to the end of the line from a match perspective). While we do have to be careful not to have a file called total, it will do the job for us here:
→ wc -l * | grep -v ' total$'
3 a.txt
4 b.txt
1 c.dat
2 d.txt
5 e.dat
→Same result. Nice.
Summing by extension
Now we have some clean and predictable input to pass to another program. We'll use awk which is a very useful and powerful text processing tool, along with its sibling sed. The wonderful programming language Perl took inspiration from both awk and sed and other text processing tools, as it happens.
It may be interesting to you to know that
awk's initials are from the authors, Aho, Weinberger and Kernighan, three luminaries from Bell Labs, the birthplace of C and Unix. On the Tech Aloud podcast, you'll find an episode entitled "C, the Enduring Legacy of Dennis Ritchie - Alfred V. Aho - 07 Sep 2012" to which you may enjoy listening.
awk reads lines from STDIN (standard input) and is used often to rearrange fields in those lines, or otherwise process them. In this case we're going to read in the output from our pipeline so far, and get awk to start out by splitting each one up into separate pieces, so that we go from this:
3 a.txt
4 b.txt
1 c.dat
2 d.txt
5 e.dat
to this:
3 a txt
4 b txt
1 c dat
2 d txt
5 e dat
In this new state we can now distinguish the file extensions, and thereby have a chance to sum the line counts by them.
To do this, we use the -F switch which allows us to define what we want the "field separator" to be, what character (or which characters) we want awk to split each line on. In our case we want to split on space, and also period. So we do the following, specifying a simple in-line awk script as the main parameter:
→ wc -l * | head -n -1 | awk -F '[\ .]' '{print $2, $NF}'
3 txt
4 txt
1 dat
2 txt
5 datWe have to escape the space in the list of delimiters, hence the
\escape character.
What the script ({ print $2, $NF }) is doing is simply printing out field number 2 and the last field. We specify field number 2 ($2) because there's an empty field number one, because we've split on space. We get the last field by specifying $NF, which represents "the number of fields".
Note that for every line of input, we get a line of output. This is deliberate - awk executes the bit in curly brackets for each line it processes. But we can also get awk to do something at the beginning, or at the end, of processing. Consider a change from the simple script that we have now:
{ print $2, $NF }
to this:
{ counts[$NF]+=$2 }
END { for (ext in counts) print ext, "->", counts[ext] }
This will accumulate the individual line counts for each file into an associative array counts keyed by the extension (e.g. txt). The { counts[$NF]+=$2 } part runs for each line coming in on STDIN. Then at the end of processing, the block with the for loop is executed, printing out the totals by extension.
Let's see this in action:
→ wc -l * | head -n -1 | awk -F'[\ .]' '{counts[$NF]+=$2}
> END {for (ext in counts) print ext, "->", counts[ext]}'
dat -> 6
txt -> 9The
>symbol at the start of the second line is the "continuation" character, put there by the shell to tell me it was expecting more input, after I'd hit enter at the end of the first line (because I hadn't yet closed the opening single quote).
Wrapping up
And there we have it. We only used a few features of awk but they are certainly powerful enough for this task, when combined into a pipeline with wc and head (or grep).
I'd encourage you to spend some time in a text-based Unix or Unix-like environment. All the major PC operating systems today have such environments available, either directly (with Linux and macOS) or indirectly via VMs (with ChromeOS and Windows 10).
The future is terminal. Happy pipelining!